
Improving software HCS 411GITS is not really about applying a few random speed tricks. The better approach is to find where the system is wasting time, memory, database effort, or developer attention, then fix those areas in a controlled way. In many cases, the biggest improvement does not come from rewriting the whole platform. It comes from measuring the right thing, cleaning up the slow parts, and making future changes safer.
HCS 411GITS is usually discussed as a technical, workflow-heavy system that may involve calibration processes, Git-based development, project tracking, resource management, and structured deployment. That kind of software can become slow or unstable for many reasons. A database query may be doing too much work. A background task may be holding memory longer than it should. A release process may be creating bugs because staging and production do not match. So the question is not only “how do we make it faster?” It is also “how do we make it easier to trust?”
What HCS 411GITS Improvement Should Actually Mean?
When people want to know how to improve software HCS 411GITS, they are usually looking for practical ways to make the system run better. But “better” can mean several things. It can mean faster screens, fewer crashes, more reliable deployments, cleaner Git workflows, easier debugging, or lower server load. A useful improvement plan should cover all of these, not just one.
A common mistake is treating performance as a single issue. For example, a team may blame the server when the real issue is a slow query. Another team may keep optimizing code while the real problem is poor test coverage that makes every release risky. Improvement should be measured across speed, stability, maintainability, and release confidence.
Quick Improvement Checklist
| Area | What to Check | Why It Matters |
| Code | Hot paths, loops, memory usage | Finds real bottlenecks |
| Database | Queries, indexes, payload size | Reduces slow responses |
| Testing | Unit, integration, system tests | Prevents regressions |
| Deployment | CI/CD, containers, rollback | Makes releases safer |
| Monitoring | Errors, latency, resources | Shows what happens in production |
| Documentation | Decisions, workflows, setup | Helps future teams maintain it |
Start With Real Performance Data
The first step is to measure the current state of HCS 411GITS before making any changes. This sounds basic, but it is where many teams go wrong. They start with opinions instead of evidence. One developer thinks the database is slow, another blames the frontend, and someone else wants a bigger server. Without data, all of them may be partly right and still miss the real bottleneck.
Track response times, memory usage, CPU load, database latency, failed jobs, error logs, and the slowest workflows. Do not look only at averages. Average response time can hide the parts users actually complain about. The slower edge cases, such as reports, calibration actions, exports, or approval steps, often reveal the real pain.
Profile the Code Before Rewriting It
Code profiling shows which functions or processes consume the most time and resources. It is tempting to rewrite old code because it looks messy, but messy code is not always the slowest code. Sometimes the ugliest module barely affects performance, while one clean-looking loop quietly runs thousands of times.
Profiling should happen with realistic data, not tiny test samples. If HCS 411GITS handles project history, calibration records, or stored workflow data, test it with records similar to production. Small test data can make bad code look fine. Large, older, uneven data usually tells the truth.
Fix Database Queries That Do Too Much Work
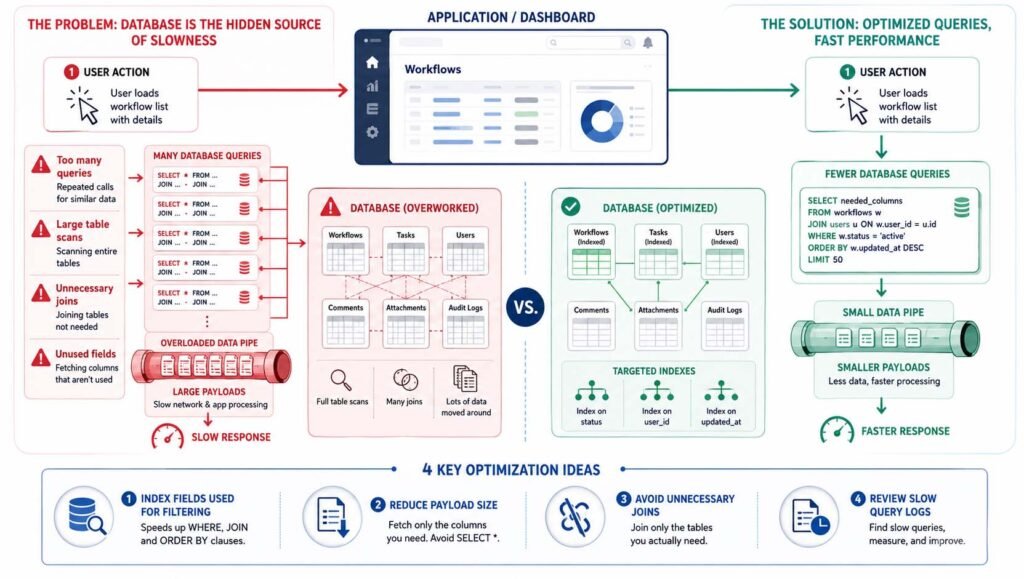
For many workflow-heavy systems, the database is the hidden source of slowness. The application may feel sluggish because it keeps asking the database for too much data, too often. A single user action might trigger multiple queries when a carefully written query would suffice.
Look for missing indexes, large table scans, unnecessary joins, and payloads that include fields the page does not even use. Query optimization is not glamorous, but it often gives faster results than rewriting application code. Still, adding indexes everywhere is not smart either. Index the fields that are actually used for filtering, sorting, searching, and joining.
Use Caching Carefully, Not Blindly
Caching can make HCS 411GITS much faster when the same data is repeatedly requested. User permissions, configuration values, status labels, and stable reference data are good examples. Instead of hitting the database repeatedly, the system can serve that data from memory.
But caching is not a magic fix. It can mask poor database design, and if handled poorly, it can serve outdated information. The team should decide what gets cached, how long it stays cached, and what clears it. A simple rule helps: cache stable data first, then move carefully toward anything that changes often.
Reduce Connection Overhead With Pooling
Connection pooling is one of those improvements that users never notice directly, but they feel the difference. Without pooling, the software may repeatedly open and close database connections, wasting time and server resources. A pool reuses connections, allowing the system to respond more smoothly under load.
The pool size matters. Too small, and users wait. Too large, and the database gets overwhelmed. The right configuration depends on traffic, query duration, database limits, and server capacity. It should be tuned from monitoring data, not copied from a random setup.
Make Testing Part of Performance Work
Testing is often treated as a quality task, separate from performance. That is a narrow view. Good tests make performance work safer because developers can refactor slow modules without fear of breaking important workflows.
HCS 411GITS should have tests at different levels. Unit tests check smaller rules and functions. Integration tests check database calls, APIs, permissions, and module interactions. System tests test full workflows from the user’s perspective. Automated tests should run before release, ideally within a CI/CD pipeline, so problems are caught early rather than after deployment.
Use CI/CD to Stop Risky Releases
A CI/CD pipeline does not automatically improve software HCS 411GITS, but it improves how changes move through the system. Every code change can be built, tested, scanned, and deployed consistently. That reduces the chance of a rushed manual release causing production issues.
For HCS 411GITS, the pipeline should validate code quality, run automated tests, check dependencies, and deploy to a staging environment first. Branch rules and pull requests also matter. A good Git workflow keeps changes traceable, reviewable, and easier to roll back if something goes wrong.
Use Containers for Consistent Environments
Containerization can help improve software HCS 411GITS by reducing environment mismatch. A system may work on a developer machine but fail in staging due to a different runtime version, a missing dependency, or configuration differences. Containers reduce that problem by packaging the application with the environment it expects.
Still, containers should not be oversold. Docker or similar tools do not automatically make slow software fast. What they do well is make deployment more predictable. Resource limits, memory settings, storage access, and networking still need attention. A badly configured container can create its own performance problems.
Watch Memory and Cleanup Behavior
Memory issues often appear slowly. The software runs fine at first, then gets heavier, slower, and less stable over time. This can happen when background tasks keep references too long, temporary files are not cleaned up, database connections stay open, or large objects remain in memory after they are no longer needed.
HCS 411GITS should be tested for long-running behavior, not just startup performance. A short test may pass easily while an eight-hour workload exposes leaks, garbage collection pauses, queue buildup, or resource exhaustion. Automated cleanup routines can help, but they should be monitored to confirm they are actually working.
Monitor Production Like a Feedback Loop
Once a release goes live, monitoring should show whether the change helped. Track application response time, database latency, memory usage, CPU load, failed jobs, container health, and error patterns. If HCS 411GITS has specific workflows, such as calibration, reporting, approval, or project synchronization, monitor them directly.
The goal is not to collect dashboards for decoration. Monitoring should help the team decide what to fix next. If database latency rises after a release, investigate queries. If memory continues to climb throughout the day, review cleanup and object handling. If errors spike after merges, review the deployment and testing process.
Also Read: Windows 10 Display Issues: How to Fix Common Screen Problems
Document the Decisions People Usually Forget
Documentation is not only user guides and setup notes. For HCS 411GITS, the most valuable documentation often explains the rationale for specific technical choices. Why was this cache timeout set? Why is this container memory limit higher than expected? Why does this workflow retry three times before failing?
Those notes save time later. Teams change, people forget, and performance fixes can look strange months after they were made. Document requirements, architecture, deployment steps, Git workflow rules, database changes, known bottlenecks, and rollback procedures. Good documentation reduces the risk of future improvements.
Improve Failure Behavior, Not Just Speed
One overlooked part to improve software HCS 411GITS is how the system behaves when something goes wrong. A slightly slower system that fails safely may be more valuable than a fast system that corrupts data or gives confusing errors. Especially in calibration-heavy or workflow-driven software, correctness matters as much as speed.
Test failure cases on purpose. What happens if a database write fails halfway? What if a user submits the same action twice? What if a background job stops during processing? Better retry logic, safer transactions, clearer logs, and user-friendly error messages can make the system feel far more reliable.
Read More Tech Articles on: Zingyzon.com
FAQs
How do I improve the performance of software HCS 411GITS?
Start with measurement. Track slow workflows, database latency, memory usage, CPU load, and error patterns. Then profile the code, optimize the database, improve testing, and monitor each release to confirm whether the change actually helped.
Why does HCS 411GITS become slow over time?
It may slow down because of growing data, inefficient queries, memory leaks, poor cleanup, repeated database calls, or heavier user workflows. Long-running systems often degrade gradually, so endurance testing and production monitoring are important.
Can CI/CD improve HCS 411GITS?
Yes, but mainly by making changes safer and more consistent. CI/CD can automate builds, tests, scans, and deployments to catch bugs earlier. It also makes rollback easier when a release causes issues.
Is containerization enough to fix HCS 411GITS issues?
No. Containerization helps with consistent deployment, but it does not automatically fix bad queries, memory leaks, weak testing, or poor architecture. It works best when combined with profiling, monitoring, and disciplined release practices.